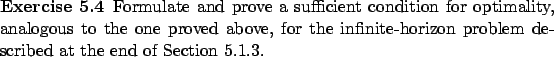Together, the HJB equation--written as (5.10) or (5.12)--and the Hamiltonian maximization condition (5.14) constitute necessary conditions for
optimality. It should be clear that all we proved so far is their
necessity. Indeed, defining ![]() to be the value function, we
showed that it must satisfy the HJB equation.
Assuming further that an optimal control exists, we showed that it
must maximize the Hamiltonian along the optimal trajectory. However, we will see next that these conditions
are also sufficient for optimality.
Namely, we will establish the following sufficient condition for optimality: Suppose that
a
to be the value function, we
showed that it must satisfy the HJB equation.
Assuming further that an optimal control exists, we showed that it
must maximize the Hamiltonian along the optimal trajectory. However, we will see next that these conditions
are also sufficient for optimality.
Namely, we will establish the following sufficient condition for optimality: Suppose that
a
![]() function
function
![]() satisfies the HJB equation
satisfies the HJB equation
Then
To prove this result, let us first apply (5.20) with
![]() . We know from (5.22) that
along
. We know from (5.22) that
along ![]() , the infimum is a minimum and it is achieved at
, the infimum is a minimum and it is achieved at ![]() ; hence we have, similarly to (5.13),
; hence we have, similarly to (5.13),
We can move the
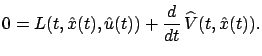
Integrating this equality with respect to
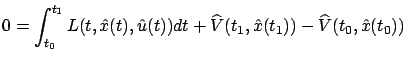
which, in view of the boundary condition for
or
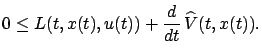
Integrating over
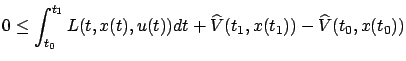
or
We can regard the function
![]() as providing a tool for verifying optimality of candidate optimal controls (obtained, for example, from the maximum principle). This optimality is automatically global. A simple modification of the above argument yields that
as providing a tool for verifying optimality of candidate optimal controls (obtained, for example, from the maximum principle). This optimality is automatically global. A simple modification of the above argument yields that
![]() is the optimal cost-to-go from an arbitrary point
is the optimal cost-to-go from an arbitrary point
![]() on the trajectory
on the trajectory ![]() .
More generally, since
.
More generally, since
![]() is defined for all
is defined for all ![]() and
and ![]() , we could use an arbitrary pair
, we could use an arbitrary pair ![]() in place of
in place of ![]() and obtain optimality with respect to
and obtain optimality with respect to ![]() as the initial condition in the same way. Thus, if we have a family of controls parameterized by
as the initial condition in the same way. Thus, if we have a family of controls parameterized by ![]() , each fulfilling the Hamiltonian maximization condition along the corresponding trajectory which starts at
, each fulfilling the Hamiltonian maximization condition along the corresponding trajectory which starts at ![]() , then
, then
![]() is the value function and it lets us establish optimality of all these controls. A typical way in which such a control family can arise is from a state feedback law description; we will encounter a scenario of this kind in Chapter 6.
The next two exercises offer somewhat different twists on the above sufficient condition for optimality.
is the value function and it lets us establish optimality of all these controls. A typical way in which such a control family can arise is from a state feedback law description; we will encounter a scenario of this kind in Chapter 6.
The next two exercises offer somewhat different twists on the above sufficient condition for optimality.
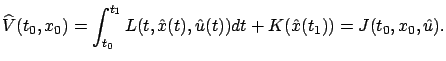
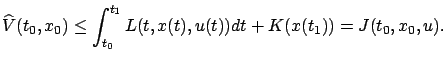
![\begin{Exercise}
Suppose that a control $\hat u:[t_0,t_1]\to U$, the correspondi...
...0,x_0)$\ is the optimal cost and $\hat u$\ is an optimal control.
\end{Exercise}](img1655.gif)