The dynamic programming approach is quite general, but to fix ideas we first present it for the purely discrete case. Consider a system of the form
where
The most naive approach to this problem is as follows: starting
from ![]() , enumerate all possible trajectories going forward up
to time
, enumerate all possible trajectories going forward up
to time ![]() , calculate the cost for each one, then compare them
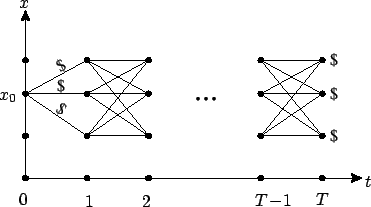
and select the optimal one. Figure 5.1 provides a
visualization of this scenario. It is easy to estimate the
computational effort required to implement such a solution: there
are
, calculate the cost for each one, then compare them
and select the optimal one. Figure 5.1 provides a
visualization of this scenario. It is easy to estimate the
computational effort required to implement such a solution: there
are ![]() possible trajectories and we need
possible trajectories and we need ![]() additions to compute the cost for each one, which results
in roughly
additions to compute the cost for each one, which results
in roughly ![]() algebraic operations.
algebraic operations.
We now examine an alternative approach, which might initially
appear counterintuitive: let us go backward in time. At ![]() ,
terminal costs are known for each
,
terminal costs are known for each ![]() . At
. At ![]() , for each
, for each
![]() we find to which
we find to which ![]() we should jump so as to have the
smallest cost (the one-step running cost plus the terminal cost).
Write this optimal ``cost-to-go" next to each
we should jump so as to have the
smallest cost (the one-step running cost plus the terminal cost).
Write this optimal ``cost-to-go" next to each ![]() and mark the
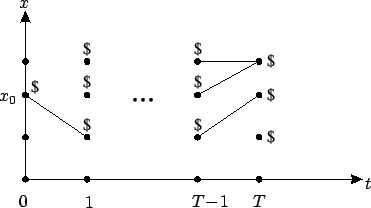
selected path (see Figure 5.2). In case of more
than one path giving the same cost, choose one of them at random.
Repeat these steps for
and mark the
selected path (see Figure 5.2). In case of more
than one path giving the same cost, choose one of them at random.
Repeat these steps for
![]() , working with the
costs-to-go computed previously in place of the terminal costs.
, working with the
costs-to-go computed previously in place of the terminal costs.
We claim that when we are done, we will have generated an optimal
trajectory from each ![]() to some
to some ![]() . The justification of
this claim relies on the principle of optimality, an observation
that we already made during the proof of the maximum principle
(see page
. The justification of
this claim relies on the principle of optimality, an observation
that we already made during the proof of the maximum principle
(see page ![[*]](crossref.gif) ). In the present context this principle
says that for each time step
). In the present context this principle
says that for each time step ![]() , if
, if ![]() is a point on an
optimal trajectory then the remaining decisions (from time
is a point on an
optimal trajectory then the remaining decisions (from time ![]() onward) must constitute an optimal policy with respect to
onward) must constitute an optimal policy with respect to ![]() as
the initial condition. What the principle of optimality does for
us here is guarantee that the paths we discard going backward
cannot be portions of optimal trajectories. On the other hand, in
the previous approach (going forward) we are not able to discard
any paths until we reach the terminal time and finish the
calculations.
as
the initial condition. What the principle of optimality does for
us here is guarantee that the paths we discard going backward
cannot be portions of optimal trajectories. On the other hand, in
the previous approach (going forward) we are not able to discard
any paths until we reach the terminal time and finish the
calculations.
Let us assess the computational effort associated with this
backward scheme. At each time ![]() ,
for each state
,
for each state ![]() and each control
and each control ![]() we need to add
the cost of the corresponding transition to the
cost-to-go already computed for the resulting
we need to add
the cost of the corresponding transition to the
cost-to-go already computed for the resulting
![]() . Thus, the number of required operations is
. Thus, the number of required operations is ![]() . Comparing this with the
. Comparing this with the ![]() operations needed for the
earlier forward scheme, we conclude that the backward computation
is more efficient for large
operations needed for the
earlier forward scheme, we conclude that the backward computation
is more efficient for large ![]() , with
, with ![]() and
and ![]() fixed. Of
course, the number of operations will still be large if
fixed. Of
course, the number of operations will still be large if ![]() and
and
![]() are large (this is the ``curse of
dimensionality").
are large (this is the ``curse of
dimensionality").
Actually, the above comparison is not really accurate because the
backward scheme provides much more information: it finds the
optimal policy for every initial condition ![]() , and in fact it
tells us what the optimal decision is at every
, and in fact it
tells us what the optimal decision is at every ![]() for all
for all ![]() .
We can restate this last property as follows: the backward scheme
yields the
optimal control policy in the form of a state feedback
law. In the forward
scheme, on the other hand, to handle all initial conditions we
would need
.
We can restate this last property as follows: the backward scheme
yields the
optimal control policy in the form of a state feedback
law. In the forward
scheme, on the other hand, to handle all initial conditions we
would need ![]() operations, and we would still not cover all
states
operations, and we would still not cover all
states ![]() for
for ![]() ; hence, a state feedback is not obtained.
We see that the backward scheme fulfills the objective formulated
in Bellman's quote at the beginning of this chapter.
This recursive scheme serves as an example of
the general method of dynamic programming.
; hence, a state feedback is not obtained.
We see that the backward scheme fulfills the objective formulated
in Bellman's quote at the beginning of this chapter.
This recursive scheme serves as an example of
the general method of dynamic programming.